





This is a summary of what I learned in Full Stack Web Developer (Nanodegree) on Udacity. This article is about SQL and Data Modeling for Web
I. Interacting with Databases
1. Overview
Here are the three core topics we'll be covering in this article:
1.1. Interacting with a (remote) database:
Backend developers need to interact with databases on a regular basis in order to manipulate and maintain the models behind their web applications.
In working with databases, we'll need to use a Database Management System (DBMS)
A Database Management System (DBMS) is simply software that allows you to interact with a database (access or modify the data in that database).
There are many different Database Management Systems out there, but the particular DBMS we'll be using is called PostgreSQL (or simply Postgres).
1.2. Database Application Programming Interfaces (DBAPIs)
Once we've looked at the basics of interacting with a database, we'll need to understand how to interact with that database from another language or web server framework (such as Python, NodeJS, Ruby on Rails, etc.). This is where DBAPIs come in.
1.3. psycopg2
Finally, we'll get some experience working with the widely used psycopg2 library, which will allow us to interact with a database from Python.
psycopg2 is a database adapter that allows us to interact with a Postgres database from Python.
There is a lot going on between all of the components. The diagram below can give you a feel for how it is all connected
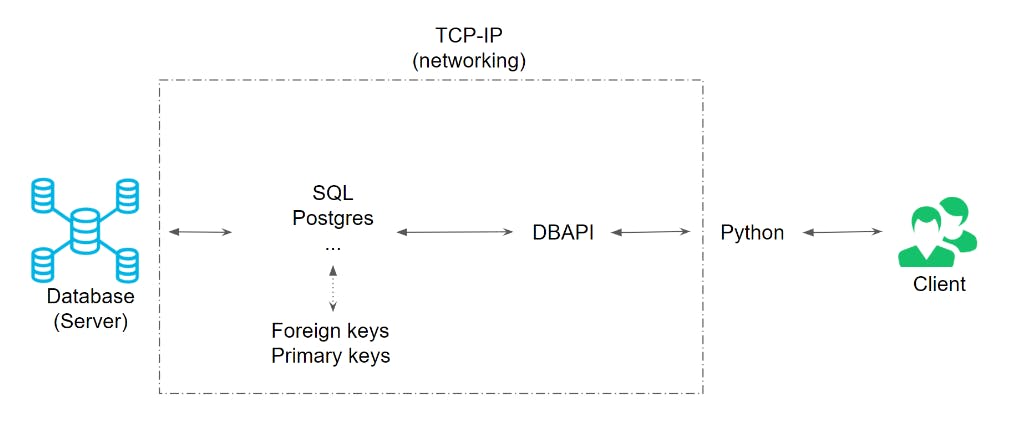
2. Relational Databases
- A database is a collection of data
- A database system is a system for storing collections of data in some organized way.
Database properties:
- This is a property that is known as Persistence (allowing access later, after it was created)
- Shared source of truth accessible by many users
- Ability to store many types of data (efficiently)
- Concurrency control (handling multiple DB actions at once)
Relational Databases:
- All data is stored in tables
- Every table is characterized by a list of columns with data types per column, and its set of data (organized in rows)
- Comes with rules for enforcing data integrity, such as constraints and triggers.
3. Primary keys & Foreign Keys
Primary Key
- The primary key is the unique identifier for the entire row, referring to one or more columns.
- If there are more multiple columns for the primary key, then the set of primary key columns is known as a composite key.
Foreign Key
- A primary key in another (foreign) table.
- Foreign keys are used to map relationships between tables.
4. Client-Server Model
In order to build database-backed web applications, we first need to understand how servers, clients, and databases interact.
A major part of this is the client-server model, so let's look at that first. The basic idea is very simple, and looks something like this:
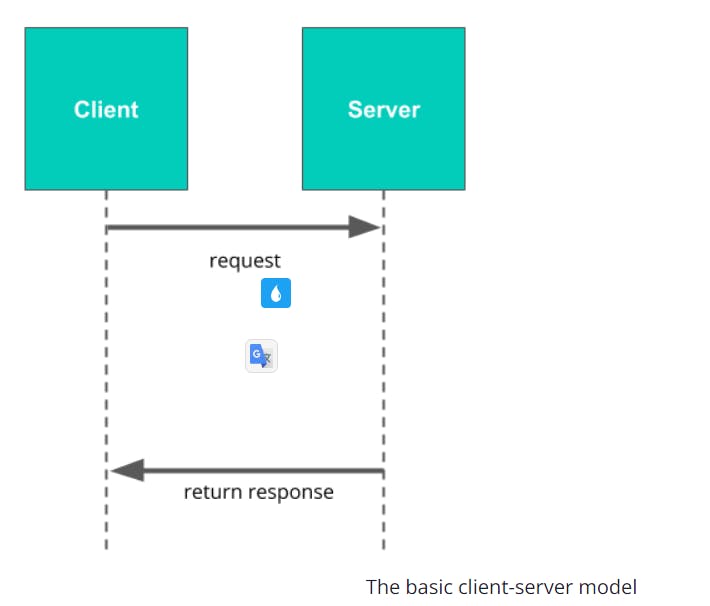
A server is a centralized program that communicates over a network (such as the Internet) to serve clients.
And a client is a program (like the web browser on your computer) that can request data from a server.
When you go to a web page in your browser, your browser (the client) makes a request to the server—which then returns the data for that page
Relational database systems follow a client-server model:
Servers, Clients, Hosts
- In a Client-Server Model, a server serves many clients.
- Servers and clients are programs that run on hosts.
- Hosts are computers connected over a network (like the internet!).
Requests and Responses
- A client sends a request to the server
- The server's job is to fulfill the request with a response it sends back to the client.
- Requests and responses are served via a communication protocol, which sets up the expectations and rules for how the communication occurs between servers and clients.
Relational Database Clients
- A database client is any program that sends requests to a database
- In some cases, the database client is a webserver! When your browser makes a request, the webserver acts as a server (fulfilling that request), but when the webserver requests data from the database, it is acting as a client to that database and the database is the server (because it is fulfilling the request).
Basically, we call things clients when they are making a request and servers when they are fulfilling a request. Since a web server can do both, it sometimes acts as a server and sometimes acts as a client.
5. TCP/IP
In this section, we'll look at the suite of communication protocols that are used to transfer data over the Internet. These communication protocols are most often referred to as TCP/IP, which is an abbreviation that refers to the two main protocols involved—Transmission Control Protocol (TCP) and Internet Protocol (IP).
Takeaways TCP/IP is a suite of communication protocols that are used to connect devices and transfer data over the Internet.
TCP/IP uses:
- IP addresses: An IP address identifies the location of a computer on a network.
- Ports: A port is a location on the recipient computer, where data is received.
While an IP address tells you where to find a particular computer, it doesn't tell you specifically where on that computer a particular connection should be made—that's what port numbers are for.
Some port numbers you should know:
- Port 80: The port number most commonly used for HTTP requests. For example, when a client makes a request to a web server, this request is usually sent through port 80.
- Port 5432: The port number used by most database systems; default port for Postgres.
6. Connections and Sessions in TCP/IP
Takeaways
- TCP/IP is connection-based, meaning all communications between parties are arranged over a connection. A connection is established before any data transmission begins.
Over TCP/IP, we'll always need to establish a connection between clients and servers in order to enable communications. Moreover:
Deliveries over the connection are error-checked: if packets arrive damaged or lost, then they are resent (known as retransmission).
Connecting starts a session. Ending the connection ends the session.
- In a database session, many transactions can occur during a given session. Each transaction does work to commit changes to the database (updating, inserting, or deleting records).
Aside: the UDP Protocol The internet also offers the UDP protocol. UDP stands for User Datagram Protocol. UDP is much simpler than TCP: hosts on the network send data (in units called datagrams) without any connections needing to be established.
TCP vs UDP If TCP is like building roads between houses before sending packages between them, then UDP is much like sending over a carrier pigeon from house to house in order to deliver messages: you don't have much control over the pigeon once it flies away -- will the pigeon will fly the right direction, drop your package into the dirt, or encounter attacking bald-eagle during flight. On the other hand, USD has less overhead than TCP / building a highway.
When speed is more important than reliability, especially when applications need to stream very small amounts of information quickly (smaller packages of information mean fewer issues with reliability), then UDP is preferred. A lot of real-time streaming applications, (e.g. live TV streaming, Voice over IP (VoIP)) prefer UDP over TCP. Since UDP does not need to retransmit lost datagrams, nor does it do any connection setup, there are fewer delays over UDP than TCP. TCP's continuous connection is more reliable but has more latency.
7. Transactions
Takeaways
- Databases are interacted using client-server interactions, over a network
- Postgres uses TCP/IP to be interacted with, which is connection-based
- We interact with databases like Postgres during sessions
- Sessions have transactions that commit work to the database.
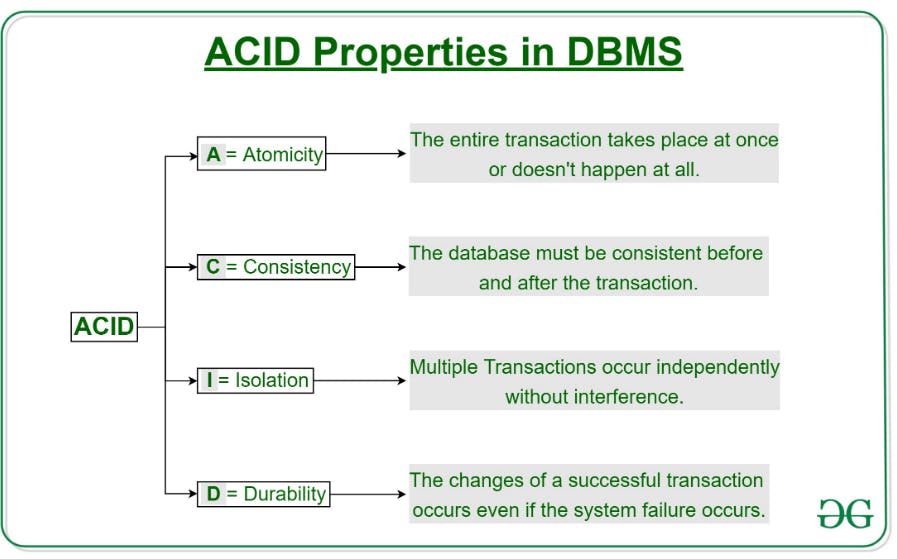
Transactions capture logical bundles of work. Work is bundled into transactions so that in case of system failures, data in your database is still kept in a valid state (by rolling back the entire transaction if any part of it fails). To ensure a database is consistent before and after work is done to it, databases use atomic transactions, and actions like commits and rollbacks to handle failures appropriately. Transactions are, in other words, ACID.
8. Postgres
Let's deep dive into what Postgres is
- Postgres is an open-source, general-purpose, and object-relational database management system, considered by many to be the most advanced open-source database system available. It's a relational database system extended with object-oriented features, that works across operating systems.
Object-relational support includes support for arrays (multiple values in a single column), and inheritance (child-parent relationships between tables).
- Built in 1977, it is lauded for being highly stable, requiring minimal effort to maintain compared to other systems.
- Widely used, everywhere: by Apple, Cisco, Etsy, Microsoft, Yahoo, Reddit, Instagram, Uber,... and many others.
- Comprehensive support for the SQL standard.
- Transaction-based: operations on the database are done through atomic transactions.
- Has multi-version concurrency control, avoiding unnecessary locking when multiple writes are happening to the database at once (avoiding waiting times for access to the database)
Postgres lets you have several databases available for reading from and writing to, at once.
- Offers great performance and many indexing capabilities for optimizing query performance
- PostgreSQL is also often just called Postgres.
9. DBAPIs and psycopg2
Takeaways
We will sometimes want to interact with our database and use its results in a specific programming language. E.g. to build web applications or data pipelines in a specific language (Ruby, Python, Javascript, etc.). That's where DBAPIs come in.
A DBAPI
- provides a standard interface for one programming language (like Python) to talk to a relational database server.
- Is a low-level library for writing SQL statements that connect to a database
- is also known as database adapters
Different DBAPIs exist for every server framework or language + database system
Database adapters define a standard for using a database (with SQL) and using the results of database queries as input data in the given language.
- Turn a selected SELECT * from some_table; list of rows into an array of objects in Javascript for say a NodeJS adapter; or a list of tuples in Python for a Python adapter.
Examples across languages and server frameworks
- For Ruby (e.g. for Sinatra, Ruby on Rails): pg
- For NodeJS: node-postgres
- For Python (e.g. for Flask, Django): pyscopg2
II. SQLAlchemy Basics
1. Overview
Takeaways + A Note on ORMS
SQLAlchemy
- SQLAlchemy is the most popular open-source library for working with relational databases from Python.
- It is one type of ORM library, AKA an Object-Relational Mapping library, which provides an interface for using object-oriented programming to interact with a database.
Other ORM libraries that exist across other languages include popular choices like javascript libraries Sequelize and Bookshelf.js for NodeJS applications, the ruby library ActiveRecord, which is used inside Ruby on Rails, and CakePHP for applications written on PHP, amongst many other such ORMs.
SQLAlchemy:
- Features function-based query construction: allows SQL clauses to be built via Python functions and expressions.
- Avoid writing raw SQL. It generates SQL and Python code for you to access tables, which leads to less database-related overhead in terms of the volume of code you need to write overall to interact with your models.
- Moreover, you can avoid sending SQL to the database on every call. The SQLAlchemy ORM library features automatic caching, caching collections, and references between objects once initially loaded.
The diagram below can give you insight into where SQL Alchemy and ORM are in the big picture.
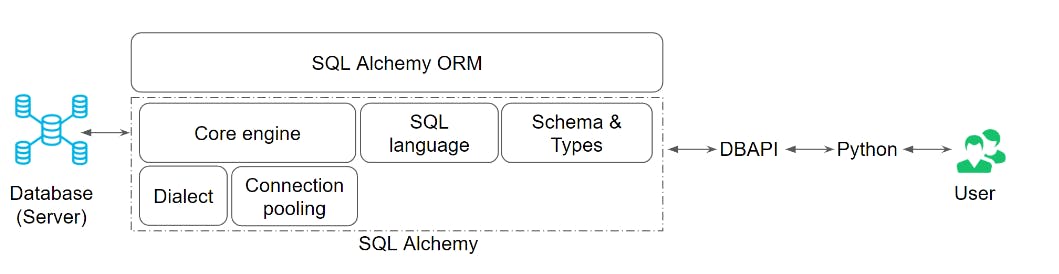
2. Layers of Abstraction
SQLAlchemy is broken down into various layers of abstraction. Let's go through each layer in depth.
Without SQLAlchemy, we'd only use a DBAPI to establish connections and execute SQL statements. Simple, but not scalable as complexity grows.
SQLAlchemy offers several layers of abstraction and convenient tools for interacting with a database.
SQLAlchemy vs psycopg2
- SQLAlchemy generates SQL statements
- psycopg2 directly sends SQL statements to the database.
- SQLAlchemy depends on psycopg2 or other database drivers to communicate with the database, under the hood.
SQLALchemy lets you traverse through all 3 layers of abstraction to interact with your database.
- Can stay on the ORM level
- Can dive into database operations to run customized SQL code specific to the database, on the Expressions level.
- Can write raw SQL to execute, when needed, on the Engine level: Can more simply use psycopg2 in this case
We'll go over every layer of abstraction in SQLAlchemy and what they offer.
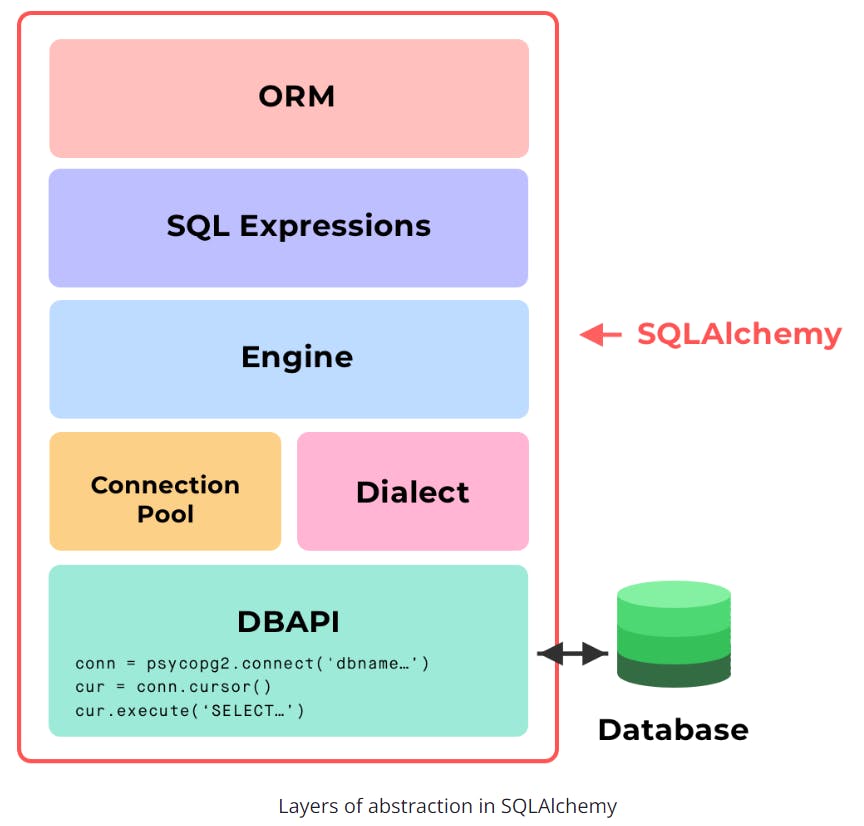
Layers of SQLAlchemy
- DBAPI
- The Dialect
- The Connection Pool
- The Engine
- SQL Expressions
- SQLAlchemy ORM (optional)
3. The Dialect
When we're using SQLAlchemy, we can forget generally speaking about the database system that we're using, allowing us to use SQL lite or Postgres or generally switch out the database system whenever we need to. The reason why we can do this is because of the dialects
Dialects allow the flavor of SQL that we're using to get abstracted away from us because the dialect's layer controls the quirks and flavor of the specific database system that we're using.
The dialect is the system SQLAlchemy uses to communicate with various types of DBAPI implementations and databases. The sections that follow contain reference documentation and notes specific to the usage of each backend, as well as notes for the various DBAPIs.
All dialects require that an appropriate DBAPI driver is installed.
4. The connection Pool
With a connection pool, the opening and closing of connections and which connection you are using when you're executing statements within a session are completely abstracted away from you.
As a result of having a connection pool:
- Connections are easily reused after they are started. This avoids the problem of continually opening and closing connections every time we want to make data changes to our database.
- A connection pool also easily handles dropped connections for us, for example, when we have network issues.
- It also helps us avoid doing very many small calls to the database when we're continually assigning changes to the database, which can be very slow.
A connection pool is a technique used to maintain long-running connections in memory for efficient re-use, as well as management for the total number of simultaneous connections an application might use.
5. The Engine
The Engine
- 1 of 3 main layers for how you may choose to interact with the database.
- Is the lowest level layer of interacting with the database, and is much like using the DBAPI directly. Very similar to using psycopg2, managing a connection directly.
Moreover,
- The Engine in SQLAlchemy refers to both itself, the Dialect and the Connection Pool, which all work together to interface with our database.
- A connection pool gets automatically created when we create an SQLAlchemy engine.
6. SQL Expressions
- Instead of sending raw SQL (using the Engine), we can compose python objects to compose SQL expressions, instead.
- SQL Expressions still involves using and knowing SQL to interact with the database.
7. SQLAlchemy ORM
SQLAlchemy ORM
- Lets you compose SQL expressions by mapping python classes of objects to tables in the database
- Is the highest layer of abstraction in SQLALchemy.
- Wraps the SQL Expressions and Engine to work together to interact with the database
- Will be used in this course, so we can know how to use ORM libraries in general.
Moreover, SQLAlchemy is split into two libraries:
- SQLAlchemy Core
- SQLAlchemy ORM (Object Relational Mapping library). SQLALchemy ORM is offered as an optional library, so you don't have to use the ORM in order to use the rest of SQLAlchemy.
- The ORM uses the Core library inside
- The ORM lets you map from the database schema to the application's Python objects +The ORM persists objects into corresponding database tables]
SQLAlchemy Layers of Abstraction Overview (Diagram)

8. SQLAlchemy Data Types
SQLAlchemy has its own data types that we should become familiar with. In SQLAlchemy, there is a one-to-one parity between an SQLAlchemy datatype and the data type that would be understandable in the semantics of the particular database system that you're linking your SQLAlchemy engine to.
- db.integer, that's the integer type for the database system that we're using.
- db.string, where you can optionally pass in a number that represents the maximum length of that string should be. For Postgress in particular, we're able to specify a variable character string, so we can omit the size variable, so that setting db.string with nothing in it, specifies a varchar data field.
- db.text for longer text
- db.DateTime for date time objects
- floats
- Booleans
- PickleTypes
- large binaries for storing large binary data or pickled Python objects.
III. SQLAlchemy ORM in Depth
SQLAlchemy Object Lifecycle
Takeaways
- Within a session, we create transactions every time we want to commit work to the database.
- Proposed changes are not immediately committed to the database and instead, go through stages to allow for undos.
- The ability to undo is allowed via db.session.rollback()
Stages:
- Transient: an object exists, it was defined....but not attached to a session or database (yet).
- Pending: Some type of action has occurred but we have not yet decided to make it permanent yet. An object was attached to a session. "Undo" becomes available via db.session.rollback(). This means we can still clear any work that has been done so far. An object stays in this state until a flush happens!
- Flushed: Translating actions(pending changes) into SQL commands that are ready to be committed. Nothing happens in the actual database yet. The only thing that can do that is 'commit'
- Committed: manually called for all pending changes to persist to the database permanently.
A flush takes pending changes and translates them into commands ready to be committed. It occurs: when you call Query. Or on db.session.commit()
A commit leads to persisted changes on the database + lets the db.session start with a new transaction.
When a statement has been flushed already, SQLAlchemy knows not to do the work again of translating actions to SQL statements.
IV. Migrations
Takeaways
- Migrations deal with how we manage modifications to our data schema, over time.
- Mistakes to our database schema are very expensive to make. The entire app can go down, so we want to: quickly roll back changes, and test changes before we make them
- A Migration is a file that keeps track of changes to our database schema (structure of our database). Offers version control on our schema.
Upgrades and rollbacks
- Migrations stack together in order to form the latest version of our database schema
- We can upgrade our database schema by applying migrations
- We can roll back our database schema to a former version by reverting migrations that we applied

Migrations are changes to the database data and schema that are saved into a file. This file can be applied to rollback or apply those changes
Migrations
- encapsulate a set of changes to our database schema, made over time.
- are uniquely named
- are usually stored as local files in our project repo, e.g. a migrations/ folder
- There should be a 1-1 mapping between the changes made to our database, and the migration files that exist in our migrations/ folder.
- Our migrations files set up the tables for our database.
- All changes made to our DB should exist physically as part of migration files in our repository.
Migration command-line scripts There are generally 3 scripts needed, for
- migrate: creating a migration script template to fill out; generating a migration file based on changes to be made
- upgrade: applying migrations that hadn't been applied yet ("upgrading" our database)
- downgrade: rolling back applied migrations that were problematic ("downgrading" our database)
Migration library for Flask + SQLAlchemy
- Flask-Migrate is our library for migrating changes using SQLAlchemy. It uses a library called Alembic underneath the hood.
Flask-Migrate & Flask-Script
- Flask-Migrate (flask_migrate) is our migration manager for migrating SQLALchemy-based database changes
- Flask-Script (flask_script) lets us run migration scripts we defined, from the terminal
Steps to get migrations going
- Initialize the migration repository structure for storing migrations
- Create a migration script (using Flask-Migrate)
- (Manually) Run the migration script (using Flask-Script)
Why use migrations?
Without migrations:
- We do heavy-handed work, creating and recreating the same tables in our database even for minor changes
- We can lose existing data in older tables we dropped
With migrations:
- Auto-detects changes from the old version & new version of the SQLAlchemy models
- Creates a migration script that resolves differences between the old & new versions
- Gives fine-grain control to change existing tables
This is much better, because
- We can keep existing schema structures, only modifying what needs to be modified
- We can keep existing data
- We isolate units of change in migration scripts that we can roll back to a “safe” db state
V. CRUD operation and Model View Controller (MVC)
1. CRUD operation
CRUD in IT stands for Create, Read, Update and Delete - a set of operations that generally constitutes a fundamental structure of a module.
While there can be additional specific operations in a module, the CRUD operations are considered the essential basic operations on any generic module.
For example, consider a user module in general. The general use cases one can think of are, creating a user (C), fetching a user’s details to display them (R), editing/updating a user (U), or deleting a user (D).
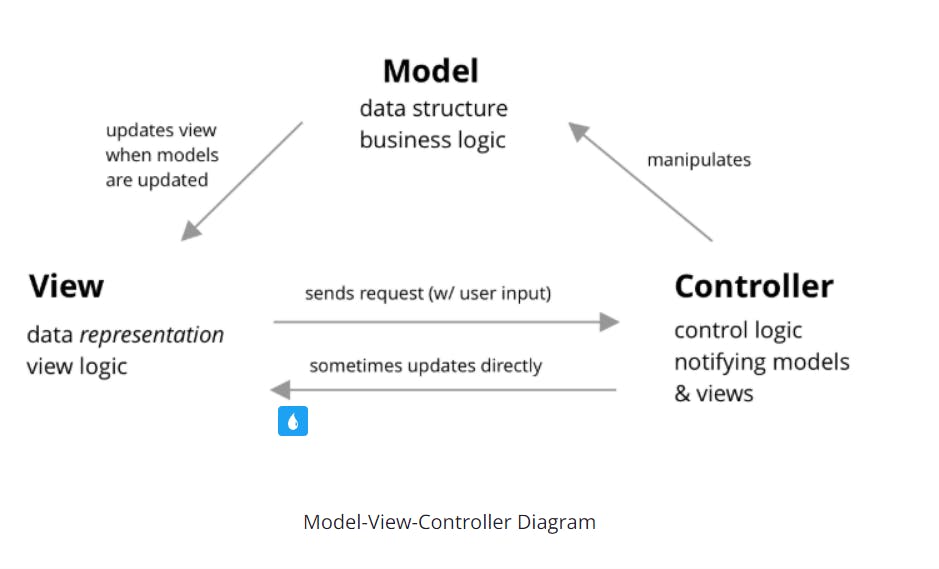
2. Model view controller (MVC)
Takeaways
- MVC stands for Model-View-Controller, a common pattern for architecting web applications
- Describes the 3 layers of the application we are developing
Layers
- Models manage data and business logic for us. What happens inside models and databases, capturing logical relationships and properties across the web app objects
- Views handle display and representation logic. What the user sees (HTML, CSS, JS from the user's perspective)
- Controllers: routes commands to the models and views, containing control logic. Control how commands are sent to models and views, and how models and views wound up interacting with each other.
Glossary
- MVC, or Model-View-Controller, is a design and architectural pattern that breaks up an application into three elements: the model(the data), the view(the graphical interface that users see), and the controller(the code-logic behind the app) It is an industry-standard web development framework used heavily throughout the world.
- Ajax allows web pages to be updated fast through asynchronously exchanging small amounts of data back and forth with the server. It allows only a part of a web page to be updated without reloading the entire page.
- CRUD Any database should be able to (C)reate, (R)ead, (U)pdate, and (D)elete data.
- A session represents all interactions with the database and actually implements a “holding zone” for all the data objects that were affected during this time. They can be finalized (made permanent) by committing the changes, or rolling back if unwanted'
- XMLHttpRequest (XHR) objects are used to interact with servers in order to get data from a URL (or page) without having to do an actual full page refresh. Web pages can update just a small part of a page without interrupting what the user is doing. XMLHttpRequest is used heavily in AJAX programming.
- Migrations are code-based strategies that allow you to manipulate the schema or data in a database after it has already been created and has data in it. They are useful for recording changes, as well as providing a way to "roll back" changes. There can be several migration files "stacked" on top of one another in order.